



DynamicScheduler组件
组件介绍
Dynamic Scheduler 是容器服务 TKE 基于 Kubernetes 原生 Kube-scheduler Extender 机制实现的动态调度器插件,可基于 Node 真实负载进行预选和优选。在 TKE 集群中安装该插件后,该插件将与 Kube-scheduler 协同生效,有效避免原生调度器基于 request 和 limit 调度机制带来的节点负载不均问题
部署在集群内的 Kubernetes 对象
最主要的是两个Deployment
[root@VM-2-45-tlinux ~]# kubectl get deployment -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
dynamic-scheduler 1/1 1 1 90s
node-annotator 1/1 1 1 90s
组件原理
动态调度器基于 scheduler extender 扩展机制,从 Prometheus 监控数据中获取节点负载数据,开发基于节点实际负载的调度策略,在调度预选和优选阶段进行干预,优先将 Pod 调度到低负载节点上。该组件由 node-annotator 和 Dynamic-scheduler 构成
node-annotator
node-annotator 组件负责定期从监控中拉取节点负载 metric,同步到节点的 annotation。如下图所示:
Dynamic-scheduler
Dynamic-scheduler 是一个 scheduler-extender,根据 node annotation 负载数据,在节点预选和优选中进行过滤和评分计算。
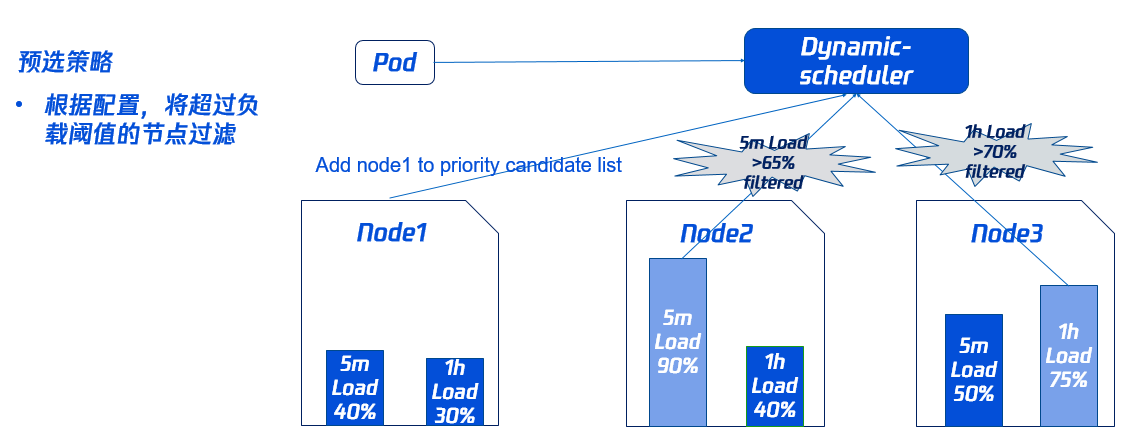
预选策略
为了避免 Pod 调度到高负载的 Node 上,需要先通过预选过滤部分高负载的 Node(其中过滤策略和比例可以动态配置,具体请参见本文 组件参数说明)。 如下图所示,Node2 过去5分钟的负载,Node3 过去1小时的负载均超过对应的域值,因此不会参与接下来的优选阶段。
预选阈值配置 实在安装组件时候设置的,如果保持默认配置,则是全部节点都参与预选
优选策略
同时为了使集群各节点的负载尽量均衡,Dynamic-scheduler 会根据 Node 负载数据进行打分,负载越低打分越高。 如下图所示,Node1 的打分最高将会被优先调度(其中打分策略和权重可以动态配置,具体请参见本文 组件参数说明)。
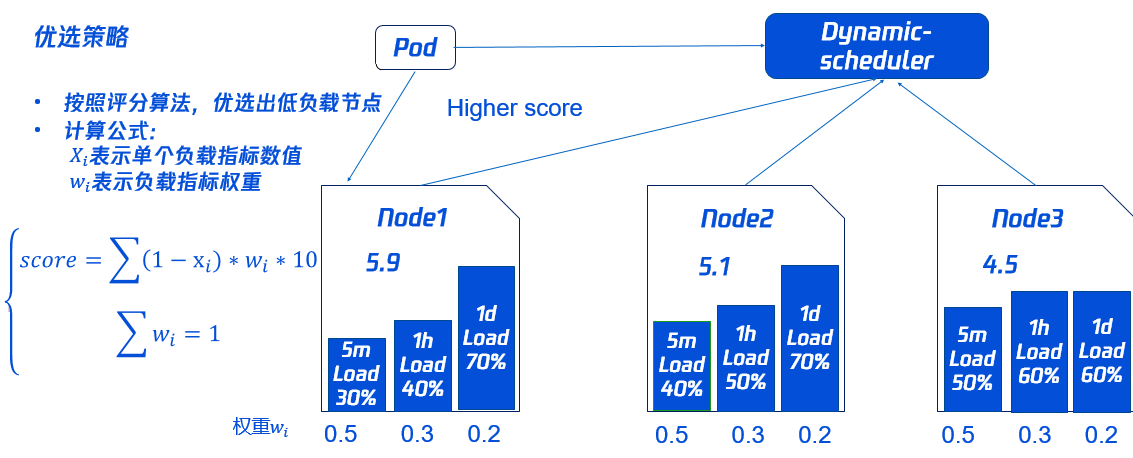
比如上面得分如下
score(node1)=(1-0.3)*0.5*10+(1-0.4)*0.3*10+(1-0.7)*0.2*10 = 5.9分 (Xi 表示的是当前负载百分比 Wi表示的是设置的权重)
score(node2)=(1-0.4)*0.5*10+(1-0.5)*0.3*10+(1-0.7)*0.2*10 = 5.1分
score(node2)=(1-0.5)*0.5*10+(1-0.6)*0.3*10+(1-0.6)*0.2*10 = 4.5分
依赖部署
Dynamic Scheduler 动态调度器依赖于 Node 当前和过去一段时间的真实负载情况来进行调度决策,需通过 Prometheus 等监控组件获取系统 Node 真实负载信息。在使用动态调度器之前,需要部署 Prometheus 等监控组件。在容器服务 TKE 中,您可按需选择采用自建的 Prometheus 监控服务或采用 TKE 推出的云原生监控。
聚合规则配置
配置前通过PromQL语句查询相关聚合数据是否存在
查询方式:登陆Granfana>Expore
cpu_usage_active:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[30s])) * 100) #默认是有数据
100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes) #默认是有数据
cpu-usage-5m:
max_over_time(cpu_usage_avg_5m[1h]) #没有 数据
max_over_time(cpu_usage_avg_5m[1d]) #没有 数据
cpu-usage-1m:
avg_over_time(cpu_usage_active[5m]) #没有 数据
mem-usage-5m:
max_over_time(mem_usage_avg_5m[1h]) #没有 数据
max_over_time(mem_usage_avg_5m[1d]) #没有 数据
mem-usage-1m:
avg_over_time(mem_usage_active[5m]) #没有 数据
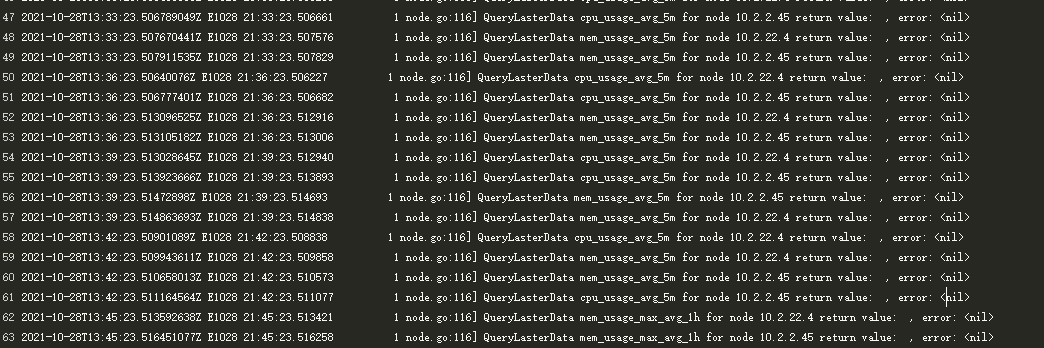
查看node-annotato组件日志
添加聚合规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: dynamicscheduler
spec:
groups:
- name: cpu_mem_usage_active
interval: 30s
rules:
- record: cpu_usage_active
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[30s])) * 100)
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- name: cpu-usage-5m
interval: 5m
rules:
- record: cpu_usage_max_avg_1h
expr: max_over_time(cpu_usage_avg_5m[1h])
- record: cpu_usage_max_avg_1d
expr: max_over_time(cpu_usage_avg_5m[1d])
- name: cpu-usage-1m
interval: 1m
rules:
- record: cpu_usage_avg_5m
expr: avg_over_time(cpu_usage_active[5m])
- name: mem-usage-5m
interval: 5m
rules:
- record: mem_usage_max_avg_1h
expr: max_over_time(mem_usage_avg_5m[1h])
- record: mem_usage_max_avg_1d
expr: max_over_time(mem_usage_avg_5m[1d])
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
再次通过PromQL语句查询相关聚合数据是否存在
cpu_usage_active:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[30s])) * 100) #默认是有数据
100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes) #默认是有数据
cpu-usage-5m:
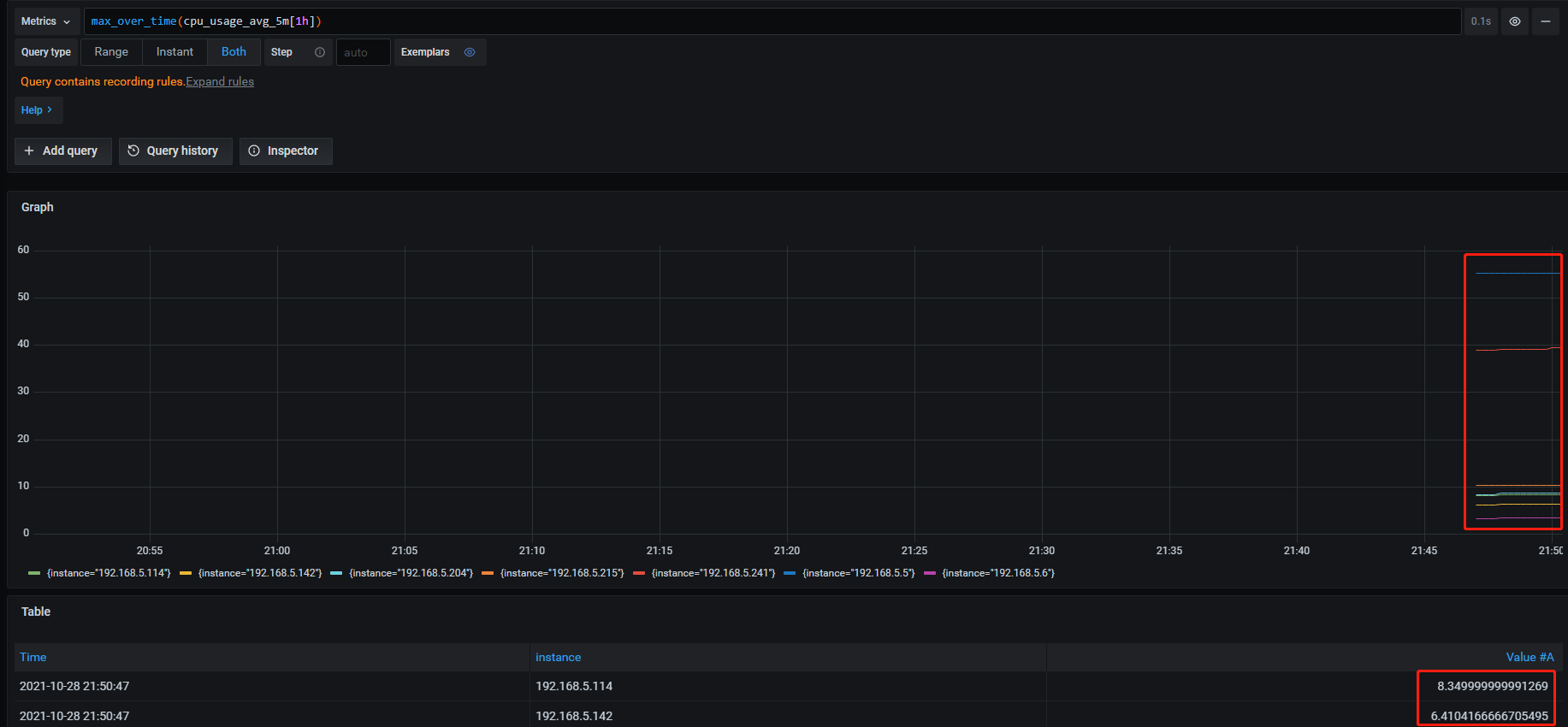
max_over_time(cpu_usage_avg_5m[1h]) #有 数据
max_over_time(cpu_usage_avg_5m[1d]) #有 数据
cpu-usage-1m:
avg_over_time(cpu_usage_active[5m]) #有 数据
mem-usage-5m:
max_over_time(mem_usage_avg_5m[1h]) #有 数据
max_over_time(mem_usage_avg_5m[1d]) #有 数据
mem-usage-1m:
avg_over_time(mem_usage_active[5m]) #有 数据
node-annotator 将 metric同步到节点的 annotation
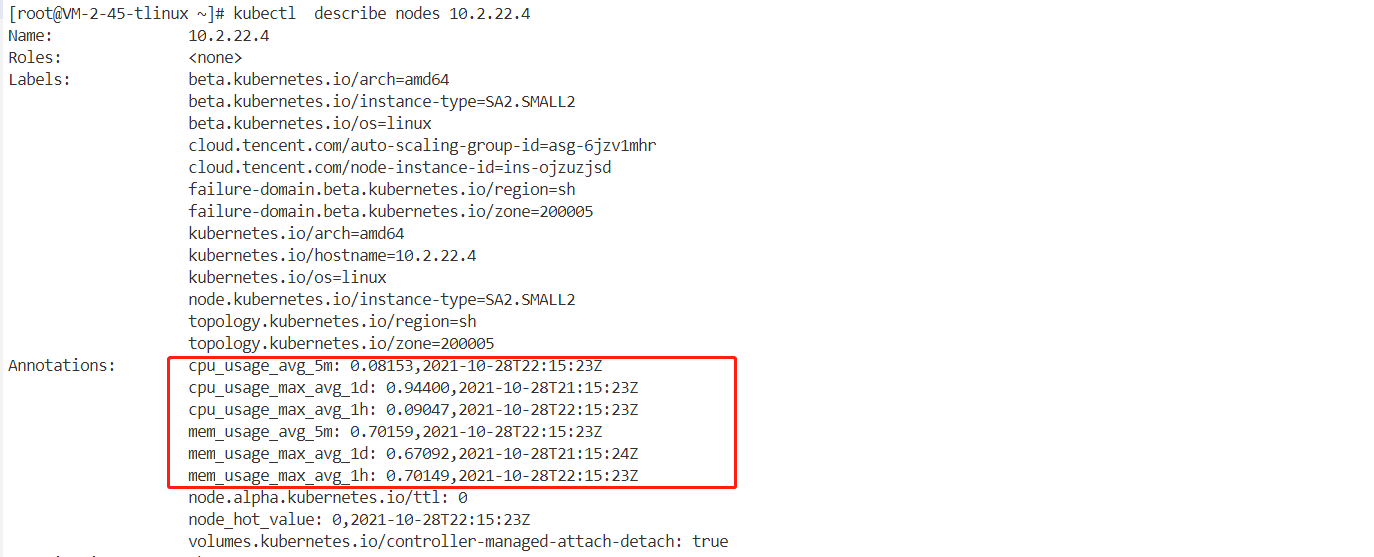
[root@VM-2-45-tlinux ~]# kubectl describe nodes 10.2.22.4
会有如下annotation:
Annotations: cpu_usage_avg_5m: 0.08320,2021-10-28T21:54:23Z #cpu5分钟
cpu_usage_max_avg_1d: 0.94400,2021-10-28T21:15:23Z #cpu 1天
cpu_usage_max_avg_1h: 0.94400,2021-10-28T21:45:23Z #cpu 1小时
mem_usage_avg_5m: 0.69384,2021-10-28T21:54:23Z #内存 5分钟
mem_usage_max_avg_1d: 0.67092,2021-10-28T21:15:24Z #内存 1天
mem_usage_max_avg_1h: 0.67092,2021-10-28T21:15:23Z #内存 1小时
组件日志也是显示正常

DeScheduler 组件
组件介绍
DeScheduler 是容器服务 TKE 基于 Kubernetes 原生社区 DeScheduler 实现的一个基于 Node 真实负载进行重调度的插件。在 TKE 集群中安装该插件后,该插件会和 Kube-scheduler 协同生效,实时监控集群中高负载节点并驱逐低优先级 Pod
[root@VM-2-45-tlinux ~]# kubectl get deployment -n kube-system | grep descheduler
descheduler 1/1 1 1 75s
使用场景
DeScheduler 通过重调度来解决集群现有节点上不合理的运行方式。社区版本 DeScheduler 中提出的策略基于 APIServer 中的数据实现,并未基于节点真实负载。因此可以增加对于节点的监控,基于真实负载进行重调度调整。
容器服务 TKE 自研的 ReduceHighLoadNode 策略依赖 Prometheus 和 node_exporter 监控数据,根据节点 CPU 利用率、内存利用率、网络 IO、system loadavg 等指标进行 Pod 驱逐重调度,防止出现节点极端负载的情况。DeScheduler 的 ReduceHighLoadNode 与 TKE 自研的 Dynamic Scheduler 基于节点真实负载进行调度的策略需配合使用。
组件原理
DeScheduler 基于 社区版本 Descheduler 的重调度思想,定期扫描各个节点上的运行 Pod,发现不符合策略条件的进行驱逐以进行重调度。社区版本 DeScheduler 已提供部分策略,策略基于 APIServer 中的数据,例如 LowNodeUtilization 策略依赖的是 Pod 的 request 和 limit 数据,这类数据能够有效均衡集群资源分配、防止出现资源碎片。但社区策略缺少节点真实资源占用的支持,例如节点 A 和 B 分配出去的资源一致,由于 Pod 实际运行情况,CPU 消耗型和内存消耗型不同,峰谷期不同造成两个节点的负载差别巨大。
因此,腾讯云 TKE 推出 DeScheduler,底层依赖对节点真实负载的监控进行重调度。通过 Prometheus 拿到集群 Node 的负载统计信息,根据用户设置的负载阈值,定期执行策略里面的检查规则,驱逐高负载节点上的 Pod
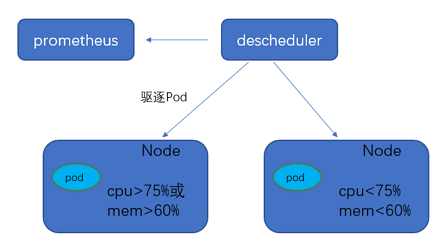
依赖部署
通过 node-exporter 实现对于 Node 指标的监控,您可按需部署 node-exporter 和 Prometheus。
聚合规则配置
配置前通过PromQL语句查询相关聚合数据是否存在
查询方式:登陆Granfana>Expore
mem_usage_active:
100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes) #存在数据
cpu-usage-1m:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) #有数据
mem-usage-1m:
avg_over_time(mem_usage_active[5m]) #有数据
如果只使用DeScheduler 组件,需要配置如下聚合
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: Descheduler
spec:
groups:
- name: cpu_mem_usage_active
interval: 30s
rules:
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- name: cpu-usage-1m
interval: 1m
rules:
- record: cpu_usage_avg_5m
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
同时使用 DynamicScheduler 和 DeScheduler 时应该配置如下规则:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: dynamicscheduler
spec:
groups:
- name: cpu_mem_usage_active
interval: 30s
rules:
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
- name: mem-usage-1m
interval: 1m
rules:
- record: mem_usage_avg_5m
expr: avg_over_time(mem_usage_active[5m])
- name: mem-usage-5m
interval: 5m
rules:
- record: mem_usage_max_avg_1h
expr: max_over_time(mem_usage_avg_5m[1h])
- record: mem_usage_max_avg_1d
expr: max_over_time(mem_usage_avg_5m[1d])
- name: cpu-usage-1m
interval: 1m
rules:
- record: cpu_usage_avg_5m
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- name: cpu-usage-5m
interval: 5m
rules:
- record: cpu_usage_max_avg_1h
expr: max_over_time(cpu_usage_avg_5m[1h])
- record: cpu_usage_max_avg_1d
expr: max_over_time(cpu_usage_avg_5m[1d])
组件日志也是显示正常
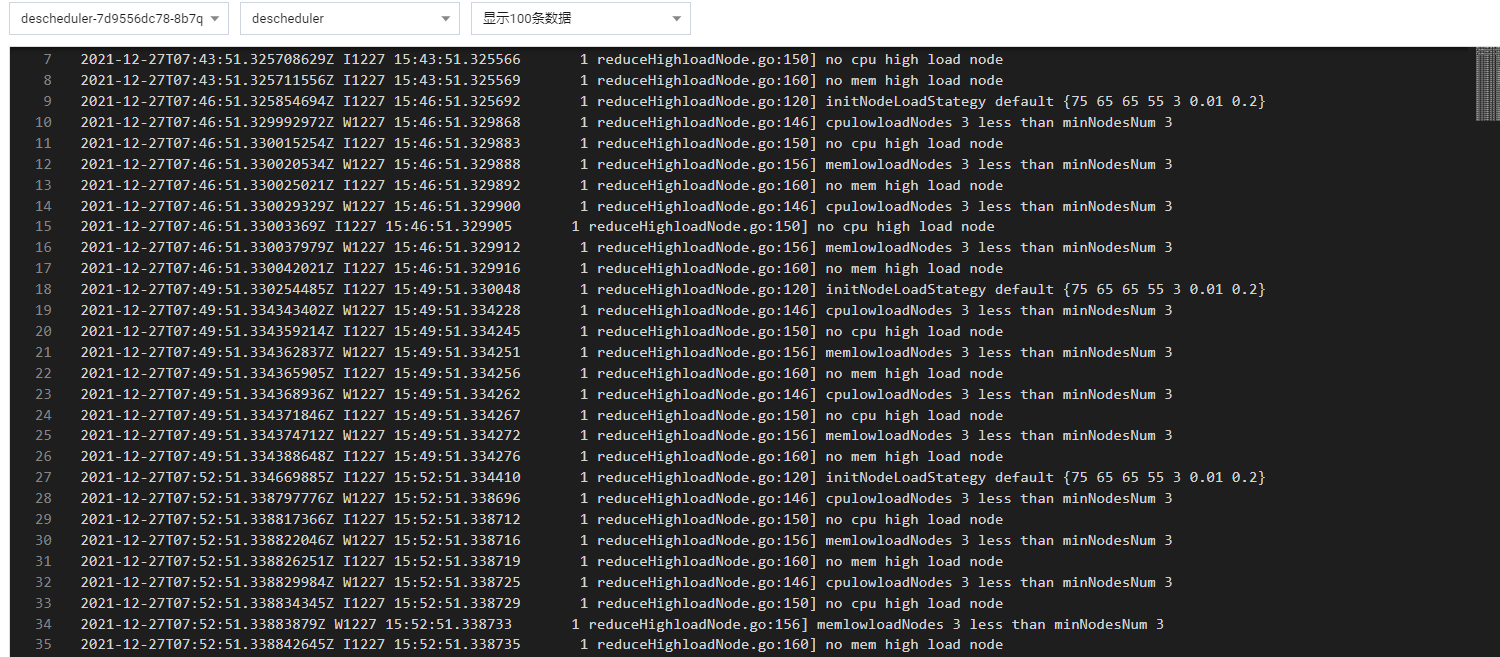
驱逐 workload
1, 需要驱逐 workload(例如 statefulset、deployment 等对象),可以设置 Annotation 如下
descheduler.alpha.kubernetes.io/evictable: 'true'
2,集群至少有4个节点 , 而且至少有3个节点负载 低于【目标利用率值】才可以驱逐 也就是集群必须四个节点,一个节点上POD高于利用阈值,其他3个节点负载低于目标利用率